Manfred Rätzmann
Mit xCase steht dem FoxPro Programmierer ein Tool zur Verfügung, mit dem Entity-Relationship Modelle erarbeitet, dokumentiert und in Datenbankstrukturen abgebildet werden können. Funktionsumfang, Stärken und Schwächen dieses Werkzeugs beleuchtet der folgende Artikel von Manfred Rätzmann.
Der Entity-Relationship Ansatz, der 1977 von Chen vorgestellt wurde, betrachtet den Datenbankentwurf auf einer logischen Ebene, die durch die Gegebenheiten des Anwendungsumfeldes bestimmt wird. Das Anwendungsumfeld, also die Organisation, deren Datenbasis modelliert werden soll, kennt fest umrissene Einheiten, wie Kunden, Lieferanten, Mitarbeiter, Produkte und so weiter. Diese Einheiten, Entitäten genannt, stehen zueinander in Beziehung. Ein Entity-Relationship Modell führt demnach diese Entitäten und deren Beziehungen zueinander auf. Der Entity-Relationship Ansatz wurde später vom Datenbankentwurf auf den gesamten Systementwurf ausgeweitet. Während beim Systementwurf inzwischen der weitergehende objektorientierte Ansatz dominiert, ist der Entity-Relationship Ansatz für den Datenbankentwurf nach wie vor aktuell, da er alle Beziehungstypen aufführt, die in den heute verbreiteten Datenbanken vorkommen.
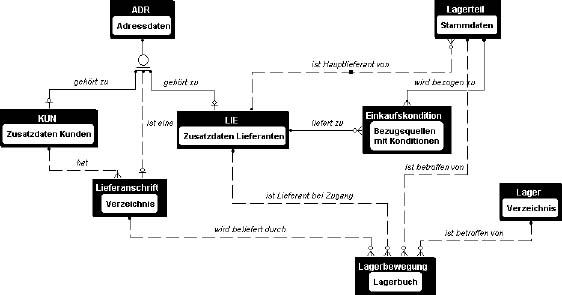
Schauen wir uns als Beispiel das in der Abbildung dargestellte Entity-Relationship Diagramm (ERD) einer Lagerverwaltung an. Die Entitäten, die im Umfeld einer Lagerverwaltung existieren, sind in diesem Fall Adressen von Kunden und Lieferanten, Lagerteile und die zu verwaltenden Lager selbst - es handelt sich hier um das Modell einer Mehrlagerverwaltung. Hinzu kommen ein Verzeichnis der Bezugsquellen und Einkaufskonditionen (wer-liefert-was) und das Lagerbuch, das die Bewegungen aller Lagerteile festhält.
Die Beziehungen zwischen diesen Entitäten werden mit durchgezogenen oder unterbrochenen Linien dargestellt, die über spezielle Symbole - auf deren Bedeutung ich später eingehen werde - mit den Entitäten verknüpft sind. Die Art der Beziehung läßt sich häufig in Worte wie "gehört zu" oder "ist Hauptlieferant von" kleiden. So werden Lagerteile von unterschiedlichen Lieferanten zu unterschiedlichen Konditionen geliefert. Ausgehend vom Lieferanten enthält das Wer-liefert-Was Verzeichnis also die Lieferkonditionen, zu denen ein Lieferant das jeweilige Lagerteil liefert. Andererseits kann ein-und-dasselbe Lagerteil von mehreren Lieferanten bezogen werden. Ausgehend vom Lagerteil enthält Wer-liefert-Was also die Bezugsquellen dieses Lagerteils und die Einkaufskonditionen, zu denen es bezogen werden kann.
Obwohl der Entity-Relationship Ansatz den Datenbankentwurf unabhängig von den Strukturen der tatsächlich benutzten Datenbank betrachtet, läßt er sich doch erheblich leichter vermitteln, wenn man diese Trennung sprachlich nicht ganz so genau nimmt. Deshalb wird im folgenden auch von Tabellen, Datensätzen und Feldern die Rede sein.
Die Entitäten lassen sich in einem xCase Diagramm auf unterschiedlichste Weise darstellen. Für mein Beispiel in Abbildung 1 habe ich die Form gewählt, in der nur der Name und die Beschreibung einer Entität ausgegeben werden. Andere Diagramme könnten die Attribute (Felder), die Schlüssel, Schlüssel und Felder, die Indizes oder die zu einer Entität gehörenden Ansichten anzeigen. Zusätzlich kann man die Herkunft von Fremdschlüsseln, die physischen Feldattribute und Abkürzungen für die Update- Delete- und Insert-Rules der Verbindungen ausgeben.
Die Beziehungen zwischen Entitäten können auf zweifache Weise unterschieden werden. Die erste Unterscheidung betrifft die Kardinalität der Beziehung. Die zweite Unterscheidung wird durch die Art der Schlüssel getroffen, die zum Knüpfen der Beziehung verwendet werden.
Die Kardinalität gibt an, mit wie vielen Entitäten eines Entitätstyps eine Beziehung hergestellt sein kann. Im einfachsten, aber seltenen Fall gehört zu einer Entität des einen Typs genau eine Entität des anderen Typs und umgekehrt. Das wäre eine 1 - 1 Beziehung, die in dem als Beispiel verwendeten Modell einer Lagerverwaltung nicht vorkommt. Andere Kardinalitätstypen sind:
Die Symbole, mit denen die Beziehungslinien an die Entitäten geknüpft sind, zeigen an, um welchen Kardinalitätstyp es sich hierbei handelt. Im theoretischen Modell ist auch eine m - n Beziehung möglich. Ein gutes Beispiel dafür ist die "liefert" Beziehung zwischen Lieferant und Lagerteil. Ein Lieferant kann mehrere (N) Lagerteile liefern, ein Lagerteil kann von mehreren (M) Lieferanten geliefert werden. Beim Datenbankdesign wird eine solche Beziehung zwischen zwei Tabellen aber immer über eine Verknüpfungstabelle aufgelöst, in unserem Fall die "wer_liefert_was" Tabelle. Deshalb werden m - n Beziehungen von xCase nicht unterstützt.
Um die Richtung einer Beziehung auszudrücken, benutzt man gerne die Parent-Child oder Eltern-Kind Benennung. Die Entität, von der die Beziehung ausgeht, ist die Eltern-Entität, die Zielentität der Beziehung ist die Kind-Entität. Die Kardinalität auf Seiten der Eltern-Entität ist immer 1, da m - n Beziehungen ausgeschlossen werden.
Die Beziehung wird realisiert durch die Übernahme des Primärschlüssels der Eltern-Entität in die Kind-Entität. Die zweite Art, Beziehungen zu unterscheiden, gibt nun an, ob dieser übernommene Primärschlüssel, der in der Kind-Entität "Foreign-Key" oder Fremdschlüssel genannt wird, in der Kind-Entität selbst wieder zum Primärschlüssel gehört. Wenn der Fremdschlüssel Teil des Primärschlüssels der Kind-Entität ist, handelt es sich um eine starke Beziehung. Ist der Fremdschlüssel im Datensatz der Kind-Entität nur ein Feld unter vielen, gehört er also nicht zum Primärschlüssel der Kind-Entität, so handelt es sich um eine schwache Beziehung. Starke Beziehungen werden von xCase mit einer durchgehenden Linie dargestellt. Schwache Beziehungen erscheinen im xCase Diagramm als gestrichelte Linien.
Eine besondere Art der Beziehung ist die Unterkategorie. Ein Adressat ist ein Kunde oder ein Lieferant (oder beides), es gibt also verschiedene Kategorien von Adressaten. xCase ermöglicht es, solche Unterkategorien zu bilden und symbolisiert diese mit dem doppelt-unterstrichenen Kreissymbol. Das Besondere an dieser Art der Beziehung ist dabei, daß hier die Primärschlüssel von Eltern- und Kind-Entität gleich sind. Die Attribute (sprich: Datenfelder) der Eltern-Entität gehören also ebenfalls zur Kind-Entität. Jede Unterkategorie fügt den Attributen der Eltern-Entität Attribute hinzu, die nur von dieser Unterkategorie benötigt werden.
Mit xCase lassen sich also Entity-Relationship Diagramme anfertigen, die bedeutend aussagekräftiger sind, als die Darstellung persistenter Beziehungen im Datenbankdesigner von Visual FoxPro. Das ist bereits eine große Hilfe für den Entwickler, der auf gute Dokumentation seines Datenbankdesigns Wert legt. Natürlich lassen sich die Diagramme aus xCase auch ausdrucken, was mit dem Datenbankdesigner ebenfalls nicht möglich ist. Zusätzlich können komplexer werdende Diagramme aufgeteilt werden, wobei Änderungen im DataDictionary sich sofort und gleichmäßig auf alle Teildiagramme auswirken. Darüber hinaus bietet xCase Funktionen an, die weit über die hervorragenden Dokumentationsmöglichkeiten hinausgehen und es zu einem unentbehrlichen Werkzeug bei der Datenbankmodellierung machen.
Wenn Sie zwei Tabellen im Datenbankdesigner von Visual FoxPro miteinander verknüpfen wollen, so definieren Sie in der Zieltabelle zunächst das Fremdschlüsselfeld und versehen es mit einem Index. Dann können Sie per Drag+Drop die Verknüpfung herstellen.
In xCase stellen Sie die Verbindung zwischen zwei Entitäten her indem Sie zunächst auf die Eltern-Entität klicken und dann auf die Kind-Entität. Um das Hinzufügen des Fremdschlüssels zur Kind-Entität und den Aufbau des benötigten Indexes kümmert sich xCase selbst. Mehr noch: Änderungen am Primärkey der Eltern-Entität werden an alle Fremdschlüssel der verknüpften Kind-Entitäten "vererbt". Wird eine Beziehung wieder gelöscht, weil Sie von Ihnen während des Modelliervorgangs als unnötig erkannt wurde, so entfernt xCase automatisch auch den für diese Beziehung benötigten Fremdschlüssel. Aus den im Modell hinterlegten Beziehungen generiert xCase den Code, der beim Löschen, Ändern oder Hinzufügen von Sätzen die referentielle Integrität sicherstellt. Anders als der von Visual FoxPro generierte Code funktioniert der xCase-Code auch bei zusammengesetzten Primärschlüsseln.
Die Entitäten eines Entity-Relationship Modells werden bei der Umsetzung des Modells in eine relationale Datenbank zu Tabellen, die Attribute einer Entität werden zu Feldern. Ausgenommen von dieser Regel sind Attribute, die als virtuelle Felder gekennzeichnet sind. Virtuelle Felder sind Ausdrücke. Ein virtuelles Feld existiert nicht als Tabellenfeld, sondern lediglich als Ausdruck im Datadictionary. Neben den virtuellen Feldern erlaubt xCase die Kennzeichnung von redundanten Feldern. Redundante Felder existieren allerdings als Tabellenfelder. Ihr Wert läßt sich aber ebenfalls anhand eines im Datadictionary hinterlegten Ausdrucks ermitteln. Die Anwendung, die virtuelle oder redundante Felder nutzen will, muß auf das xCase Dadadictionary zugreifen, um die zu diesen Feldern hinterlegten Ausdrücke auswerten zu können. Das xCase Datadictionary ist in DBF-Tabellen abgelegt, sodaß ein Zugriff aus einer FoxPro Anwendung direkt möglich ist.
In xCase wird der Typ eines jeden Feldes durch seine "Domain", zu deutsch, Domäne, Bereich oder Art, festgelegt. Die Feldtypen der Datenbank, Character, Numerisch, Währung etc., bilden dabei die Basisarten. Aus diesen Basisarten können Sie eigene Feldarten bilden, indem Sie eine Länge angeben, festlegen, ob Nullwerte erlaubt sind, eine Feldüberschrift und einen Defaultwert oder einen Validierungsausdruck samt Fehlermeldung hinterlegen. Alle diese Angaben werden unter einem Eintrag zusammengefasst, der zum Beispiel "Telefon-Nr." heißt. Weisen Sie einem Entitäten-Attribut dann die Feldart "Telefon-Nr." zu, so gelten alle Eigenschaften der Feldart "Telefon-Nr." für dieses Attribut. Änderungen an der Definition einer Feldart werden an alle Attribute der gleichen Feldart vererbt.
Bei der Definition der vorkommenden Feldarten und deren Zuordnung zu den Attributen einer Entität können alle Angaben hinterlegt werden, die nötig sind, um die zugehörige Tabelle aufzubauen und im DBC von Visual FoxPro einzutragen. xCase kann also die dem Modell entsprechende Datenbankstruktur aufbauen und bei Änderungen am Modell auch pflegen. Dabei ist sowohl der Update eines DBC aus einem xCase-Modell als auch der Update eines Modells aus einem DBC heraus möglich. Da im Modell jedoch mehr Informationen hinterlegt werden, als im DBC, empfiehlt es sich, Änderungen im Modell vorzunehmen und den DBC aus dem Modell heraus auf den neuesten Stand zu bringen.
Der Aufbau von Indizes hat nicht direkt mit der Modellierung einer Datenbank zu tun, sondern dient in erster Linie einer verbesserten Performance. Trotzdem wird die Erstellung und Verwaltung von Indizes durch xCase unterstützt. Wie oben bereits erwähnt, werden bei der Festlegung von Beziehungen zwischen Entitäten die dafür benötigten Indizes von xCase automatisch erzeugt. Ebenso erzeugt xCase Indizes für alle Primärschlüssel. Die automatische Verwaltung der Indizes bewirkt, daß sich der/die Entwickler/in um die Änderung der Indizes nicht zu kümmern braucht. Wenn Beziehungen hinzukommen oder entfallen, oder wenn die Zusammensetzung von Primärschlüsseln geändert wird, ändert xCase automatisch alle betroffenen Indizes. Im Data-Dictionary von xCase werden auch die Beziehungen mitgeführt, für die ein Index aufgebaut wurde. In einem eigenen Formular (in xCase Browser genannt) werden alle im Modell verwendeten Indizes zusammen angezeigt und können dort auch bearbeitet werden. Zur Erstellung eigener Indizes oder zur Bearbeitung der automatisch generierten Indizes bietet xCase einen sogenannten Index-Constructor an. Dieser ist vergleichbar mit dem Ausdruckseditor von Visual FoxPro, jedoch auf die Erstellung von Indexausdrücken spezialisiert. Auch selbst erstellte Indizes können mit dem Use-Constructor Flag versehen werden und werden in diesem Fall bei einer Änderung an den beteiligten Feldern ebenfalls geändert. Constructor-Indizes müssen sich jedoch immer aus Feldern der beteiligten Tabelle zusammensetzen. Der zur Optimierung gebrauchte Index DELETED() zum Beispiel kann nur als nicht gebundener, das heißt, nicht automatisch verwalteter Index aufgebaut werden.
Ansichten, oder Views, also die aus Visual FoxPro bekannten virtuellen Tabellen, werden ebenfalls von xCase unterstützt. Zusätzlich zu den Angaben über die einzubindenden Felder, die Sortierung, Gruppierung und Update-Informationen ermöglicht xCase es, Eigenschaften von Feldern in Ansichten festzulegen, die in Visual FoxPro nur programmatisch, das heißt mit Hilfe des DBSETPROP-Befehls eingestellt werden können. Das gibt dem Datenbankentwickler die Möglichkeit, Eigenschaften wie CAPTION, DEFAULT-VALUE und andere auch für Felder in Ansichten direkt im Modell festzulegen. Beim Update des DBCs aus dem Modell werden diese Eigenschaften im DBC hinterlegt.
Die automatische Verwaltung und Nutzung benannter Pfade allerdings ist eine xCase-Spezialität, die Sie in Visual FoxPro vergeblich suchen. Das xCase Handbuch beschreibt Pfade folgendermaßen: "Wenn Sie Entitäten über Beziehungen miteinander verknüpfen, dann erschaffen Sie implicit größere Strukturen: Pfade. Ein Pfad ist eine geordnete Menge von Beziehungen von einer Entität zu einer anderen Entität." Ein Pfad ist also eine Verbindung von einer Entität zu einer anderen. Ein solcher Pfad kann viele andere Entitäten berühren. So führt zum Beispiel ein Pfad von einem Kunden zu den Lagerteilen, die dieser bezogen hat, über die Lieferadressen des Kunden und die Lagerbewegungen, die diese Lieferadresse enthalten. In Beziehungen ausgedrückt, verläuft der Pfad wie folgt:
KUN hat LIEFERANSCHRIFT, LIEFERANSCHRIFT
wird beliefert durch LAGERBEWEGUNG, LAGERTEIL
ist betroffen von LAGERBEWEGUNG.
xCase zeigt den Verlauf des Pfades wahlweise über die betroffenen Beziehungen oder als englischen Satz an:
The LAGERTEIL of the LAGERBEWEGUNG(S) of the
LIEFERANSCHRIFT(S) of this KUN.
Nichts für Sprachpuristen, aber durchaus verständlich. Der Versuch, die Pfadbeschreibungen über Einträge in der INI-Datei in Deutsch geliefert zu bekommen, scheitert an den unterschiedlichen bestimmten Artikeln im Deutschen.
Wozu dienen diese Pfade? Über die Pfade findet xCase beim Bilden des SQL-SELECT zum Aufbau einer Ansicht den Weg von einer Entität zu einer anderen. Die automatische Generierung von SQL-SELECT Statements ist damit um ein vielfaches mächtiger, als die in Visual FoxPro's Ansichtsdesigner eingebauten Möglichkeiten. Um die Ansicht zu generieren, die, vom Kunden ausgehend, alle von diesem Kunden bezogenen Lagerteile aufführt, reicht es, den entsprechenden Pfad zwischen KUN und LAGERTEIL auszuwählen. Schon stehen Ihnen alle Felder aus LAGERTEIL zur Verfügung. Wählen Sie aus, welche Felder aus LAGERTEIL in der Ansicht erscheinen sollen, geben Sie in den Header-Informationen der Ansicht noch an, daß Sie bei Duplikaten nur einen Eintrag im Ergebnis sehen wollen. xCase generiert aus diesen Angaben automatisch den folgenden Befehl:
SELECT DISTINCT KUN.Kun_key, ;
Lagerteile.Lag_teil, ;
Lagerteile.Lag_vari ;
FROM KUN, Lieferanschrift, ;
Lagerbewegung,;
Lagerteil Lagerteile;
WHERE KUN.Kun_key= Lieferanschrift.Kun_key
AND Lieferanschrift.CID = Lagerbewegung.cLiefAnsID;
AND Lagerbewegung.Lag_teil = Lagerteile.Lag_teil;
AND Lagerbewegung.Lag_vari = Lagerteile.Lag_vari
Die Pfade, die sich aus den im Modell dargestellten Beziehungen ergeben, sind natürlich nicht alle sinnvoll. xCase überläßt die Auswahl der sinnvollen Pfade aus den möglichen Pfaden dem Entwickler. Bei der Erstellung der ersten Ansicht zu einer Entität sollte man also gleich alle Pfade, die von dieser Entität zu anderen Entitäten führen, prüfen und dem Verzeichnis der ausgewählten Pfade hinzufügen. Die Speicherung und Benennung der ausgewählten Pfade ist immer beidseitig, das heißt, sowohl von der Start- als auch von der End-Entität des ausgewählten Pfades nutzbar.
Die Modelle, die Sie mit xCase aufbauen, können Tabellen aus unterschiedlichen Datenbanken enthalten. In der Standardversion für FoxPro können freie Tabellen und DBC-gebundene Tabellen gemischt werden. Dies gilt auch in Ansichten, die aus diesen Tabellen zusammengesetzt werden und wird ebenfalls von Visual FoxPro unterstützt. xCase erlaubt die Verwendung von langen Tabellennamen. Bei DBC-gebundenen Tabellen werden diese Namen im DBC abgelegt. Für freie Tabellen gibt es diese Entsprechung nicht. Da die langen Tabellennamen von xCase jedoch zur Bildung des SELECT Statements für Ansichten verwendet wird, empfiehlt es sich für freie Tabellen, den physikalischen Tabellennamen auch als langen Tabellennamen einzutragen.
In der Professional Version können Tabellen aus anderen ODBC-fähigen Datenbanken ebenfalls in die Modelle eingebunden werden. Damit kann Ihr Modell neben FoxPro Tabellen auch SQL-Server oder ORACLE Tabellen enthalten. Weitere Versionen von xCase werden angeboten für Clipper & VO, VB und Access, für Delphi 2 und eine Enterprise-Version, die mehreren Entwicklern die gleichzeitige Arbeit an einem Modell erlaubt.
xCase benutzt zur Codegenerierung eine erweiterte Version der Sprache TCL. Dies ist eine Scriptgenerierungssprache, eine Sprache also, die es erlaubt, aus vorgegebenen Musterdateien, sogenannten Templates, compilierbare Programmdateien zu bilden. TCL wurde für die Zwecke von xCase um Befehle erweitert, die dem Entwickler den Zugriff auf das Datadictionary erlauben. Damit können alle Informationen, die im Modell hinterlegt sind, automatisiert in Programmcode umgewandelt werden. Die aktuelle Version von xCase enthält eine Template-Datei zur Generierung von RI-Code für Visual FoxPro. Prozeduren zur Sicherstellung der referentiellen Integrität von freien Tabellen werden derzeit (noch) nicht mitgeliefert. Der Entwickler, der sich nun an das Erlernen von TCL und an den Aufbau eigener Scripts machen will, wird ebenfalls enttäuscht sein. Zur Zeit gibt es nur eine Hilfedatei zu TCL, die die Erweiterungen der Sprache zum Zugriff auf das Datadictionary noch nicht enthält.
xCase ist ein sehr taugliches Werkzeug zur Datenmodellierung. Für die Erstellung und Pflege komplexer Datenstrukturen ist ein solches Werkzeug unerläßlich. Wünschenswert wäre auch eine Zusammenarbeit von xCase mit weiteren Entwicklungswerkzeugen wie ProMatrix oder FoxExpress.
Manfred Rätzmann entwickelt seit vielen Jahren mit Visual FoxPro. Er ist regelmäßiger Redner auf der Visual FoxPro Entwicklerkonferenz in Frankfurt/Main und veröffentlicht Artikel rund um Visual FoxPro. Seine Schwerpunkte sind die Datenmodellierung und die Entwicklung von Komponenten; sein Hauptprodukt ist die Komponentensammlung „THE LIB". Sie erreichen ihn unter 100322.2534@compuserve.com oder im dFPUG-Forum auf CompuServe.