|
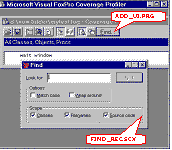
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ] [ 7 ] [ 8 ] Tuning with AddInsThe AddIn-in-question, ADD_UI.PRG, puts a button in the Coverage standard interface main dialog's Tools container, using the standard subclass's AddTool() method to do so. This is a particularly good method to add a user interface element to the standard Coverage Profiler interface -- because it will alert the main dialog to the new element and allow the main dialog to adjust its minimum height and size accordingly -- but you can use any method you prefer. The button placed in the dialog by this AddIn invokes a " Find" dialog (also available as a separate AddIn, FIND_REC.SCX). You can see both the button and the Find dialog in the figure below. Like Cov_Duration, FIND_REC illustrates an important way you can enhance or tune the Coverage Profiler: your Coverage logs often include a huge number of source records, and even a huge number of target objects and source code files. It's important to find a way to spelunk around in all this material, to find what you are looking for, as FIND_REC is designed to do.
AddIns ADD_UI.PRG and FIND_REC.SCX at work enhancing the standard Coverage Profiler interface features. File locatingAnother tuning opportunity you have in Profiler use involves its method of locating files. By default, the Coverage Profiler has an option called " Smart Pathing" turned on. This causes the Coverage Profiler to work very much like the Project Manager when it comes to finding files; once you Locate a file in a particular directory during a log's load process, the Profiler will know to return to that directory for additional files without asking you again. You should almost never need to turn off this option, unless you know your log contains information about multiple filenames with exactly the same name (including extension), and no usable path information. This may happen if your log contains information from multiple projects and you've moved the source since generating the log, or if you use non-standard extensions for your text-type source code. For example, MYPROG.PR1 and MYPROG.PR2 will both compile to MYPROG.FXP. However, even with Smart Pathing turned on, you may want to limit the number of directories you are asked to Locate. The best way to do this, if you use some standard project subdirectory structure for your source code, is to make sure your default directory is the same as your main project's, before you load a log. You will have much better results if you start out from this folder, rather than the log's folder or the COVERAGE.APP's own folder, and the Profiler will ask you fewer Locating questions.
As mentioned above, there are times when you will want to remove pathing information from a large Coverage log, because you're analyzing the log on a different machine than created the log. Here's a quick way to remove path information, even from very large logs:
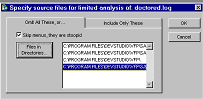
Make sure to analyze the correct filesThere is one type of file for which the Coverage Profiler must always verify location: the main file of an APP or EXE. Because of the way the generated log presents its information, there is no way for the Profiler to know for certain which PRG is really the correct main program, even though it has the name of this file. It takes a reasonable guess but always requires you to verify that guess. As you can see, there are opportunities for erroneous statistics here! Suppose you identify the wrong MAIN.PRG to the Profiler, or even just a different version of the same MAIN.PRG? If the source code is even one line different from the compiled version, your results are invalid. The Coverage Profiler will merrily assign profiling times or coverage marks against lines based on their line numbers within a file. All it knows is the line number, it has no way to validate the contents of that particular line. If you add even one comment, recompile before you generate another Coverage log. This caution applies to all source code, not just PRGs. Diskspace and workfile tuningAlong with tuning the interface and log-loading procedures, you will probably want to tune the amount of diskspace the Coverage workfiles use. One good way to do this is to limit the files analyzed to the Coverage log records that truly interest you. Cov_Omitter is a subclass of the standard Coverage Profiler interface that shows you the most efficient way to perform this task. After the engine has validated a source file that you've chosen, indicating that this file is proper log format, this subclass brings up a dialog. In this dialog you choose either the files you wish to include in the analysis or the types of files you would like to omit from the analysis.
Cov_Omitter subclass lets you choose files to exclude…
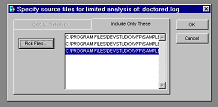
… or include files for analysis. This dialog and the choices it presents are only an illustrative sample. I do think, as the first figure above shows, that MPXs should be ignored in Coverage analysis a great deal of the time, especially if you don't write Cleanup procedures, as most people don't. The menu definition code is executed once, and is very predictable and clean as generated from GENMENU. The triggering of this code in response to ON SELECTION statements, as I've indicated in another section, cannot be properly accounted for in Coverage analysis. However you decide to set your criteria, the way this dialog achieves its results -- using low level file functions to create a stripped-down version of the log, before the engine goes to work producing any workfiles from the log -- is the way I recommend you do this kind of tuning. It will take time for the low level file functions to go through the log items and evaluate them according to whatever criteria you set, but this will be less time than it would have taken to process the original log. More important, the size of the workfiles created will be significantly reduced. Once again, remember that a few minutes' testing can create a Coverage log of many megabytes. This log sometimes translates into hundreds of megabytes of temporary workfiles. Limiting the diskspace the engine uses while creating its workfiles is arguably the most important tuning you can do. However, it's a complicated proposition. Except when you run in Unattended mode, the Coverage engine creates no persistent files unless you ask it to explicitly, using the engine's SaveTargetToDisk() method, or some other means. (In Unattended mode the engine saves the target to disk automatically, so you can look at the results whenever you're ready.) The Coverage workfiles are all cursors.
What is the significance of the fact that the Coverage engine works entirely with cursors? Simply that they're under VFP's direct control. You can direct where the cursors are created and where the bulk of the diskspace is used, with the CONFIG.FPW SORTWORK entry (one of the three TMPFILES items). Coverage's work is also impacted by the location of EDITWORK, because it massages large memofields. Although one would want to avoid running out of diskspace in the middle of an operation like Coverage analysis, because these cursors are under VFP's direct control, there is no absolute way to predict where the diskspace failure will occur. An operation may fail in the middle during the APPEND FROM of the source log into the source workfile, the indexing of the source workfile, or the import of source code into the target workfile. The amount of memory and space each cursor takes up is not stable, and the moment at which Fox deigns to write these things to disk cannot be predicted with certainty, even on multiple runs against the same log on the same machine. Even when a cursor is completely prepared, with sufficient memory VFP may still hold that entire file in memory rather than writing to disk at all. The moment at which the file is written to disk may come while you're looking at individual records, and the engine is placing marks against individual source code items. As you move to a new item in the list box, you may suddenly notice a tremendous amount of disk activity as the entire cursor is suddenly written to disk! If you're concerned about how much disk space you have available to you, you should not use the Coverage " mark all records on load" option. For large logs, you may also want to use " Fast Zoom Mode" (right click while in zoom mode to achieve this), so you can choose to mark only those records that interest you. Fast Zoom helps you with target items that have a large number of lines (like an MPR) that don't interest you at all, because you can scroll through those items without marking them. However, these items still add a great number of lines to the source cursor, and consequently to the length of time it takes to mark other target items and gather statistics, as well as the overall size of the source cursor and its indexes. This is why an earlier limiting device, such as the cov_omitter subclass, is a superior idea, if you know what you are looking for in the log. You have still more ways to tune diskspace use. The Coverage engine has three properties that determine several of the field sizes in both the source and target workfiles: THISFORMSET.iLenHostFile THISFORMSET.iLenObjClass THISFORMSET.iLenExecuting These properties receive their default values from three #DEFINEs in COV_TUNE.H: #DEFINE COV_LEN_HOSTFILE 115 #DEFINE COV_LEN_OBJCLASS 115 #DEFINE COV_LEN_EXECUTING 115 These items are set at what might be considered their maximum (115 each) because any two may be used in a concatenated key. To conserve disk space, especially in the source cursor and its CDX, you may reduce the size of these fields if you wish. However, use care, or errors will occur when filenames or object/container information is truncated. COV_TUNE.H, discussed below in the section on Coverage header files, contains copious notes and advice on tuning these values. Be sure to read the comments in this file, and then go ahead and try different values for these properties according to the rules set out in COV_TUNE.H. You need to be careful because, in many cases, truncation of cursor workfile information will not result in crashes. Instead, you'll receive incorrect statistics that look just as " real" as the right ones. |